索引缓冲
简介
在实际应用中,你将要渲染的 3D 网格通常会在多个三角形之间共享顶点。即使是绘制像矩形这样简单的东西,也会发生这种情况

绘制一个矩形需要两个三角形,这意味着我们需要一个包含 6 个顶点的顶点缓冲区。问题是两个顶点的数据需要重复,导致 50% 的冗余。对于更复杂的网格,情况会变得更糟,其中顶点平均在 3 个三角形中重复使用。这个问题的解决方案是使用索引缓冲。
索引缓冲本质上是一个指向顶点缓冲区的指针数组。它允许你重新排序顶点数据,并为多个顶点重用现有数据。上图演示了如果我们的顶点缓冲区包含四个唯一顶点中的每一个,则矩形的索引缓冲区会是什么样子。前三个索引定义了右上三角形,最后三个索引定义了左下三角形的顶点。
索引缓冲创建
在本章中,我们将修改顶点数据并添加索引数据以绘制像图中那样的矩形。修改顶点数据以表示四个角
const std::vector<Vertex> vertices = {
{{-0.5f, -0.5f}, {1.0f, 0.0f, 0.0f}},
{{0.5f, -0.5f}, {0.0f, 1.0f, 0.0f}},
{{0.5f, 0.5f}, {0.0f, 0.0f, 1.0f}},
{{-0.5f, 0.5f}, {1.0f, 1.0f, 1.0f}}
};
左上角是红色,右上角是绿色,右下角是蓝色,左下角是白色。我们将添加一个新的数组 indices 来表示索引缓冲区的内容。它应该与图中的索引匹配,以绘制右上三角形和左下三角形。
const std::vector<uint16_t> indices = {
0, 1, 2, 2, 3, 0
};
根据 vertices 中条目的数量,可以使用 uint16_t 或 uint32_t 作为索引缓冲区。由于我们使用的唯一顶点少于 65535 个,因此现在我们可以坚持使用 uint16_t。
就像顶点数据一样,索引也需要上传到 VkBuffer 中,GPU 才能访问它们。定义两个新的类成员来保存索引缓冲区的资源
VkBuffer vertexBuffer;
VkDeviceMemory vertexBufferMemory;
VkBuffer indexBuffer;
VkDeviceMemory indexBufferMemory;
我们现在要添加的 createIndexBuffer 函数几乎与 createVertexBuffer 完全相同
void initVulkan() {
...
createVertexBuffer();
createIndexBuffer();
...
}
void createIndexBuffer() {
VkDeviceSize bufferSize = sizeof(indices[0]) * indices.size();
VkBuffer stagingBuffer;
VkDeviceMemory stagingBufferMemory;
createBuffer(bufferSize, VK_BUFFER_USAGE_TRANSFER_SRC_BIT, VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT | VK_MEMORY_PROPERTY_HOST_COHERENT_BIT, stagingBuffer, stagingBufferMemory);
void* data;
vkMapMemory(device, stagingBufferMemory, 0, bufferSize, 0, &data);
memcpy(data, indices.data(), (size_t) bufferSize);
vkUnmapMemory(device, stagingBufferMemory);
createBuffer(bufferSize, VK_BUFFER_USAGE_TRANSFER_DST_BIT | VK_BUFFER_USAGE_INDEX_BUFFER_BIT, VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT, indexBuffer, indexBufferMemory);
copyBuffer(stagingBuffer, indexBuffer, bufferSize);
vkDestroyBuffer(device, stagingBuffer, nullptr);
vkFreeMemory(device, stagingBufferMemory, nullptr);
}
只有两个明显的区别。bufferSize 现在等于索引的数量乘以索引类型的大小,即 uint16_t 或 uint32_t。indexBuffer 的用法应该是 VK_BUFFER_USAGE_INDEX_BUFFER_BIT 而不是 VK_BUFFER_USAGE_VERTEX_BUFFER_BIT,这很有道理。除此之外,过程完全相同。我们创建一个暂存缓冲区来复制 indices 的内容,然后将其复制到最终的设备本地索引缓冲区。
索引缓冲区应该在程序结束时清理,就像顶点缓冲区一样
void cleanup() {
cleanupSwapChain();
vkDestroyBuffer(device, indexBuffer, nullptr);
vkFreeMemory(device, indexBufferMemory, nullptr);
vkDestroyBuffer(device, vertexBuffer, nullptr);
vkFreeMemory(device, vertexBufferMemory, nullptr);
...
}
使用索引缓冲
使用索引缓冲区进行绘制涉及到对 recordCommandBuffer 的两个更改。我们首先需要绑定索引缓冲区,就像我们对顶点缓冲区所做的那样。不同之处在于你只能有一个索引缓冲区。不幸的是,不可能为每个顶点属性使用不同的索引,所以即使只有一个属性发生变化,我们仍然必须完全复制顶点数据。
vkCmdBindVertexBuffers(commandBuffer, 0, 1, vertexBuffers, offsets);
vkCmdBindIndexBuffer(commandBuffer, indexBuffer, 0, VK_INDEX_TYPE_UINT16);
索引缓冲区使用 vkCmdBindIndexBuffer 绑定,它具有索引缓冲区、其中的字节偏移量和索引数据类型作为参数。如前所述,可能的类型是 VK_INDEX_TYPE_UINT16 和 VK_INDEX_TYPE_UINT32。
仅仅绑定索引缓冲区并不会改变任何东西,我们还需要更改绘制命令来告诉 Vulkan 使用索引缓冲区。删除 vkCmdDraw 行,并将其替换为 vkCmdDrawIndexed
vkCmdDrawIndexed(commandBuffer, static_cast<uint32_t>(indices.size()), 1, 0, 0, 0);
调用此函数与 vkCmdDraw 非常相似。前两个参数指定索引的数量和实例的数量。我们没有使用实例化,所以只需指定 1 个实例。索引的数量表示将传递给顶点着色器的顶点数量。下一个参数指定索引缓冲区中的偏移量,使用值 1 将导致显卡从第二个索引开始读取。倒数第二个参数指定要添加到索引缓冲区中索引的偏移量。最后一个参数指定实例化的偏移量,我们没有使用。
现在运行你的程序,你应该看到以下内容
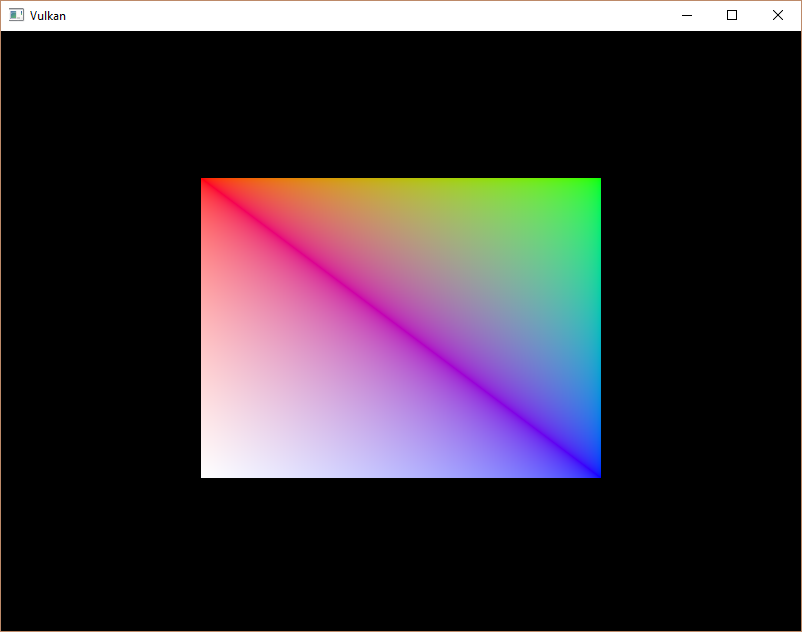
你现在知道如何通过使用索引缓冲区重用顶点来节省内存。这在未来的章节中将变得尤为重要,届时我们将加载复杂的 3D 模型。
前一章已经提到你应该从单个内存分配中分配多个资源,如缓冲区,但实际上你应该更进一步。驱动程序开发者建议 你也应该将多个缓冲区(如顶点缓冲区和索引缓冲区)存储到单个 VkBuffer 中,并在诸如 vkCmdBindVertexBuffers 之类的命令中使用偏移量。这样做的好处是你的数据在那种情况下更具有缓存友好性,因为它更靠近在一起。如果多个资源在同一渲染操作期间未使用,则甚至可以重用相同的内存块,当然前提是它们的数据已刷新。这被称为别名,一些 Vulkan 函数具有显式标志来指定你要这样做。