Compute Shader
简介
在本奖励章节中,我们将了解计算着色器。到目前为止,之前的所有章节都处理了 Vulkan 管线的传统图形部分。但与 OpenGL 等较旧的 API 不同,Vulkan 中强制支持计算着色器。这意味着您可以在每个可用的 Vulkan 实现上使用计算着色器,无论它是高端桌面 GPU 还是低功耗嵌入式设备。
这开启了图形处理器单元 (GPGPU) 上的通用计算世界,无论您的应用程序在哪里运行。GPGPU 意味着您可以在 GPU 上进行通用计算,这传统上是 CPU 的领域。但随着 GPU 变得越来越强大和灵活,许多需要 CPU 通用功能的 workload 现在可以在 GPU 上实时完成。
GPU 的计算能力可以使用的几个示例包括图像处理、可见性测试、后期处理、高级光照计算、动画、物理(例如粒子系统)等等。甚至可以将计算用于不需要任何图形输出的非可视化计算工作,例如数值计算或 AI 相关的事情。这被称为“headless compute”(无头计算)。
优势
在 GPU 上进行计算密集型计算有几个优势。最明显的一个是从 CPU 卸载工作。另一个是不需要 CPU 的主内存和 GPU 的内存之间移动数据。所有数据都可以保留在 GPU 上,而无需等待来自主内存的缓慢传输。
除了这些之外,GPU 还是高度并行的,其中一些 GPU 拥有数万个小型计算单元。这通常使它们比只有几个大型计算单元的 CPU 更适合高度并行的工作流程。
Vulkan 管线
重要的是要知道,计算与管线的图形部分完全分离。这在来自官方规范的 Vulkan 管线的以下框图中可见
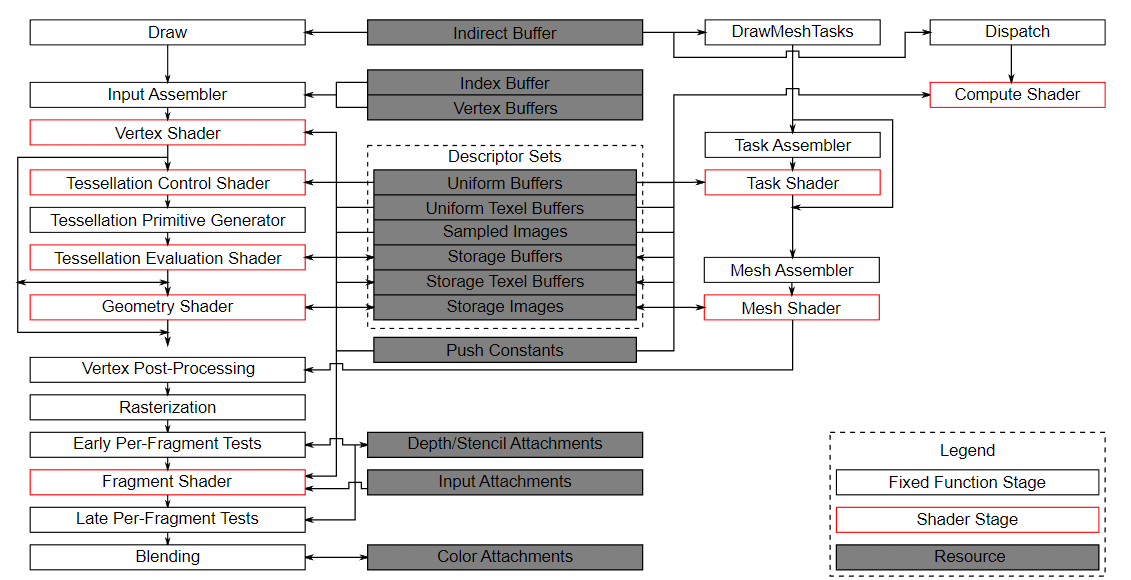
在此图中,我们可以看到左侧管线的传统图形部分,以及右侧的几个不属于此图形管线的阶段,包括计算着色器(阶段)。由于计算着色器阶段与图形管线分离,我们将能够在我们认为合适的任何地方使用它。这与例如片段着色器非常不同,片段着色器始终应用于顶点着色器的变换输出。
该图的中心还显示,例如,描述符集也由计算使用,因此我们了解到的关于描述符布局、描述符集和描述符的所有内容也适用于此处。
一个例子
我们将在本章中实现的一个易于理解的示例是基于 GPU 的粒子系统。这种系统在许多游戏中都有使用,并且通常由数千个需要以交互式帧速率更新的粒子组成。渲染这样的系统需要 2 个主要组件:顶点(作为顶点缓冲传递)和一种基于某些方程更新它们的方式。
“经典”的基于 CPU 的粒子系统会将粒子数据存储在系统的主内存中,然后使用 CPU 更新它们。更新后,顶点需要再次传输到 GPU 的内存,以便它可以在下一帧中显示更新后的粒子。最直接的方法是为每一帧重新创建具有新数据的顶点缓冲。这显然非常昂贵。根据您的实现,还有其他选项,例如映射 GPU 内存以便 CPU 可以写入(在桌面系统上称为“resizable BAR”,或在集成 GPU 上称为统一内存),或者只是使用主机本地缓冲(由于 PCI-E 带宽,这将是最慢的方法)。但无论您选择哪种缓冲更新方法,您始终需要“往返” CPU 才能更新粒子。
使用基于 GPU 的粒子系统,不再需要这种往返。顶点仅在开始时上传到 GPU,所有更新都在 GPU 的内存中使用计算着色器完成。这更快的主要原因之一是 GPU 与其本地内存之间更高的带宽。在基于 CPU 的场景中,您将受到主内存和 PCI-express 带宽的限制,这通常只是 GPU 内存带宽的一小部分。
当在具有专用计算队列的 GPU 上执行此操作时,您可以并行于图形管线的渲染部分更新粒子。这称为“异步计算”,是一个本教程未涵盖的高级主题。
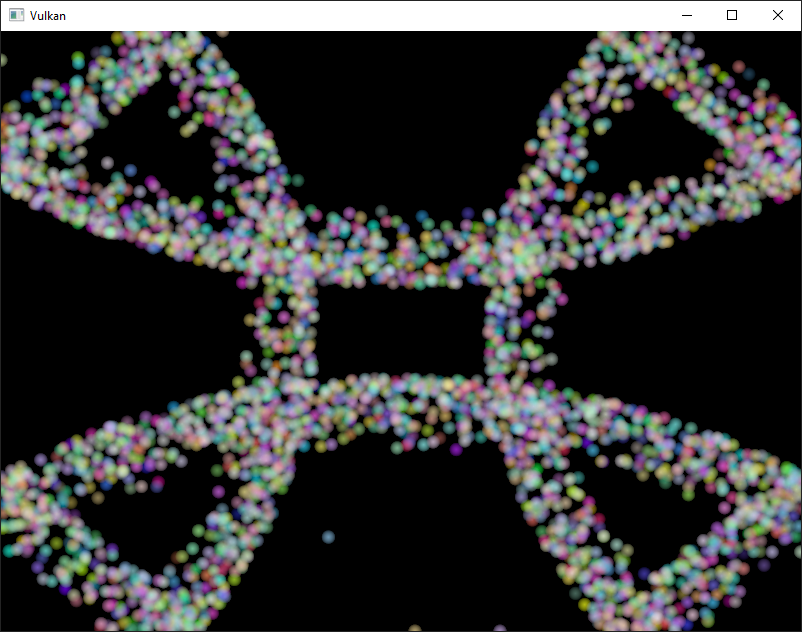
这是本章代码的屏幕截图。此处显示的粒子由 GPU 上的计算着色器直接更新,无需任何 CPU 交互
数据操作
在本教程中,我们已经了解了不同的缓冲类型,例如用于传递图元的顶点和索引缓冲,以及用于将数据传递到着色器的 uniform 缓冲。我们还使用了图像进行纹理映射。但到目前为止,我们始终使用 CPU 写入数据,并且仅在 GPU 上进行读取。
计算着色器引入的一个重要概念是任意读取和写入缓冲的能力。为此,Vulkan 提供了两种专用存储类型。
着色器存储缓冲对象 (SSBO)
着色器存储缓冲 (SSBO) 允许着色器读取和写入缓冲。使用它们类似于使用 uniform 缓冲对象。最大的区别在于您可以将其他缓冲类型别名化为 SSBO,并且它们可以任意大。
回到基于 GPU 的粒子系统,您现在可能想知道如何处理由计算着色器更新(写入)并由顶点着色器读取(绘制)的顶点,因为这两种用法似乎都需要不同的缓冲类型。
但事实并非如此。在 Vulkan 中,您可以为缓冲和图像指定多个用途。因此,为了使粒子顶点缓冲可以用作顶点缓冲(在图形通道中)和存储缓冲(在计算通道中),您只需使用这两个用途标志创建缓冲
VkBufferCreateInfo bufferInfo{};
...
bufferInfo.usage = VK_BUFFER_USAGE_VERTEX_BUFFER_BIT | VK_BUFFER_USAGE_STORAGE_BUFFER_BIT | VK_BUFFER_USAGE_TRANSFER_DST_BIT;
...
if (vkCreateBuffer(device, &bufferInfo, nullptr, &shaderStorageBuffers[i]) != VK_SUCCESS) {
throw std::runtime_error("failed to create vertex buffer!");
}
使用 bufferInfo.usage 设置的两个标志 VK_BUFFER_USAGE_VERTEX_BUFFER_BIT 和 VK_BUFFER_USAGE_STORAGE_BUFFER_BIT 告诉实现我们希望将此缓冲用于两种不同的场景:作为顶点着色器中的顶点缓冲和作为存储缓冲。请注意,我们还在其中添加了 VK_BUFFER_USAGE_TRANSFER_DST_BIT 标志,以便我们可以将数据从主机传输到 GPU。这至关重要,因为我们希望着色器存储缓冲仅保留在 GPU 内存中 (VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT),我们需要将数据从主机传输到此缓冲。
这是使用 createBuffer 辅助函数的相同代码
createBuffer(bufferSize, VK_BUFFER_USAGE_STORAGE_BUFFER_BIT | VK_BUFFER_USAGE_VERTEX_BUFFER_BIT | VK_BUFFER_USAGE_TRANSFER_DST_BIT, VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT, shaderStorageBuffers[i], shaderStorageBuffersMemory[i]);
用于访问此类缓冲的 GLSL 着色器声明如下所示
struct Particle {
vec2 position;
vec2 velocity;
vec4 color;
};
layout(std140, binding = 1) readonly buffer ParticleSSBOIn {
Particle particlesIn[ ];
};
layout(std140, binding = 2) buffer ParticleSSBOOut {
Particle particlesOut[ ];
};
在此示例中,我们有一个类型化的 SSBO,每个粒子都有一个位置和速度值(请参阅 Particle 结构)。然后,SSBO 包含无限数量的粒子,以 [] 标记。不必在 SSBO 中指定元素数量是优于例如 uniform 缓冲的优势之一。std140 是一个内存布局限定符,它确定着色器存储缓冲的成员元素在内存中如何对齐。这为我们提供了一定的保证,这是在主机和 GPU 之间映射缓冲所必需的。
在计算着色器中写入此类存储缓冲对象非常简单,类似于您在 C++ 端写入缓冲的方式
particlesOut[index].position = particlesIn[index].position + particlesIn[index].velocity.xy * ubo.deltaTime;
存储图像
请注意,我们不会在本章中进行图像处理。此段落旨在让读者意识到计算着色器也可以用于图像处理。
存储图像允许您读取和写入图像。典型的用例是将图像效果应用于纹理,进行后期处理(这反过来非常相似)或生成 mip-map。
图像也是如此
VkImageCreateInfo imageInfo {};
...
imageInfo.usage = VK_IMAGE_USAGE_SAMPLED_BIT | VK_IMAGE_USAGE_STORAGE_BIT;
...
if (vkCreateImage(device, &imageInfo, nullptr, &textureImage) != VK_SUCCESS) {
throw std::runtime_error("failed to create image!");
}
使用 imageInfo.usage 设置的两个标志 VK_IMAGE_USAGE_SAMPLED_BIT 和 VK_IMAGE_USAGE_STORAGE_BIT 告诉实现我们希望将此图像用于两种不同的场景:作为片段着色器中采样的图像和作为计算机着色器中的存储图像;
存储图像的 GLSL 着色器声明类似于例如在片段着色器中使用的采样图像
layout (binding = 0, rgba8) uniform readonly image2D inputImage;
layout (binding = 1, rgba8) uniform writeonly image2D outputImage;
此处的一些区别在于额外的属性,例如图像格式的 rgba8,readonly 和 writeonly 限定符,告诉实现我们将仅从输入图像读取并写入输出图像。最后但并非最不重要的一点是,我们需要使用 image2D 类型来声明存储图像。
然后在计算着色器中使用 imageLoad 和 imageStore 完成存储图像的读取和写入
vec3 pixel = imageLoad(inputImage, ivec2(gl_GlobalInvocationID.xy)).rgb;
imageStore(outputImage, ivec2(gl_GlobalInvocationID.xy), pixel);
计算队列族
在 物理设备和队列族章节 中,我们已经了解了队列族以及如何选择图形队列族。计算使用队列族属性标志位 VK_QUEUE_COMPUTE_BIT。因此,如果我们想要进行计算工作,我们需要从支持计算的队列族中获取队列。
请注意,Vulkan 要求支持图形操作的实现至少有一个同时支持图形和计算操作的队列族,但也可能实现提供专用的计算队列。此专用计算队列(没有图形位)暗示异步计算队列。为了使本教程对初学者友好,我们将使用可以同时执行图形和计算操作的队列。这也将使我们免于处理几种高级同步机制。
对于我们的计算示例,我们需要稍微更改设备创建代码
uint32_t queueFamilyCount = 0;
vkGetPhysicalDeviceQueueFamilyProperties(device, &queueFamilyCount, nullptr);
std::vector<VkQueueFamilyProperties> queueFamilies(queueFamilyCount);
vkGetPhysicalDeviceQueueFamilyProperties(device, &queueFamilyCount, queueFamilies.data());
int i = 0;
for (const auto& queueFamily : queueFamilies) {
if ((queueFamily.queueFlags & VK_QUEUE_GRAPHICS_BIT) && (queueFamily.queueFlags & VK_QUEUE_COMPUTE_BIT)) {
indices.graphicsAndComputeFamily = i;
}
i++;
}
更改后的队列族索引选择代码现在将尝试查找同时支持图形和计算的队列族。
然后我们可以在 createLogicalDevice 中从此队列族获取计算队列
vkGetDeviceQueue(device, indices.graphicsAndComputeFamily.value(), 0, &computeQueue);
计算着色器阶段
在图形示例中,我们使用了不同的管线阶段来加载着色器和访问描述符。通过使用 VK_SHADER_STAGE_COMPUTE_BIT 管线,可以以类似的方式访问计算着色器。因此,加载计算着色器与加载顶点着色器相同,但着色器阶段不同。我们将在接下来的段落中详细讨论这一点。计算还为描述符和管线引入了一种新的绑定点类型,名为 VK_PIPELINE_BIND_POINT_COMPUTE,我们稍后必须使用它。
加载计算着色器
在我们的应用程序中加载计算着色器与加载任何其他着色器相同。唯一真正的区别是我们需要使用上面提到的 VK_SHADER_STAGE_COMPUTE_BIT。
auto computeShaderCode = readFile("shaders/compute.spv");
VkShaderModule computeShaderModule = createShaderModule(computeShaderCode);
VkPipelineShaderStageCreateInfo computeShaderStageInfo{};
computeShaderStageInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_SHADER_STAGE_CREATE_INFO;
computeShaderStageInfo.stage = VK_SHADER_STAGE_COMPUTE_BIT;
computeShaderStageInfo.module = computeShaderModule;
computeShaderStageInfo.pName = "main";
...
准备着色器存储缓冲
早些时候我们了解到,我们可以使用着色器存储缓冲将任意数据传递给计算着色器。对于此示例,我们将粒子数组上传到 GPU,以便我们可以直接在 GPU 的内存中对其进行操作。
在 飞行帧数 章节中,我们讨论了每个飞行帧复制资源,以便我们可以保持 CPU 和 GPU 繁忙。首先,我们为缓冲对象和支持它的设备内存声明一个向量
std::vector<VkBuffer> shaderStorageBuffers;
std::vector<VkDeviceMemory> shaderStorageBuffersMemory;
然后在 createShaderStorageBuffers 中,我们调整这些向量的大小以匹配最大飞行帧数。
shaderStorageBuffers.resize(MAX_FRAMES_IN_FLIGHT);
shaderStorageBuffersMemory.resize(MAX_FRAMES_IN_FLIGHT);
完成此设置后,我们可以开始将初始粒子信息移动到 GPU。我们首先在主机端初始化粒子向量
// Initialize particles
std::default_random_engine rndEngine((unsigned)time(nullptr));
std::uniform_real_distribution<float> rndDist(0.0f, 1.0f);
// Initial particle positions on a circle
std::vector<Particle> particles(PARTICLE_COUNT);
for (auto& particle : particles) {
float r = 0.25f * sqrt(rndDist(rndEngine));
float theta = rndDist(rndEngine) * 2 * 3.14159265358979323846;
float x = r * cos(theta) * HEIGHT / WIDTH;
float y = r * sin(theta);
particle.position = glm::vec2(x, y);
particle.velocity = glm::normalize(glm::vec2(x,y)) * 0.00025f;
particle.color = glm::vec4(rndDist(rndEngine), rndDist(rndEngine), rndDist(rndEngine), 1.0f);
}
然后,我们在主机的内存中创建一个 暂存缓冲,以保存初始粒子属性
VkDeviceSize bufferSize = sizeof(Particle) * PARTICLE_COUNT;
VkBuffer stagingBuffer;
VkDeviceMemory stagingBufferMemory;
createBuffer(bufferSize, VK_BUFFER_USAGE_TRANSFER_SRC_BIT, VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT | VK_MEMORY_PROPERTY_HOST_COHERENT_BIT, stagingBuffer, stagingBufferMemory);
void* data;
vkMapMemory(device, stagingBufferMemory, 0, bufferSize, 0, &data);
memcpy(data, particles.data(), (size_t)bufferSize);
vkUnmapMemory(device, stagingBufferMemory);
使用此暂存缓冲作为源,然后我们创建每个帧的着色器存储缓冲,并将粒子属性从暂存缓冲复制到每个帧的着色器存储缓冲
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
createBuffer(bufferSize, VK_BUFFER_USAGE_STORAGE_BUFFER_BIT | VK_BUFFER_USAGE_VERTEX_BUFFER_BIT | VK_BUFFER_USAGE_TRANSFER_DST_BIT, VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT, shaderStorageBuffers[i], shaderStorageBuffersMemory[i]);
// Copy data from the staging buffer (host) to the shader storage buffer (GPU)
copyBuffer(stagingBuffer, shaderStorageBuffers[i], bufferSize);
}
}
描述符
为计算设置描述符几乎与图形相同。唯一的区别是描述符需要设置 VK_SHADER_STAGE_COMPUTE_BIT,以便计算阶段可以访问它们
std::array<VkDescriptorSetLayoutBinding, 3> layoutBindings{};
layoutBindings[0].binding = 0;
layoutBindings[0].descriptorCount = 1;
layoutBindings[0].descriptorType = VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER;
layoutBindings[0].pImmutableSamplers = nullptr;
layoutBindings[0].stageFlags = VK_SHADER_STAGE_COMPUTE_BIT;
...
请注意,您可以在此处组合着色器阶段,因此如果您希望描述符可以从顶点和计算阶段访问,例如,对于跨阶段共享参数的 uniform 缓冲,您只需设置两个阶段的位
layoutBindings[0].stageFlags = VK_SHADER_STAGE_VERTEX_BIT | VK_SHADER_STAGE_COMPUTE_BIT;
这是我们示例的描述符设置。布局如下所示
std::array<VkDescriptorSetLayoutBinding, 3> layoutBindings{};
layoutBindings[0].binding = 0;
layoutBindings[0].descriptorCount = 1;
layoutBindings[0].descriptorType = VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER;
layoutBindings[0].pImmutableSamplers = nullptr;
layoutBindings[0].stageFlags = VK_SHADER_STAGE_COMPUTE_BIT;
layoutBindings[1].binding = 1;
layoutBindings[1].descriptorCount = 1;
layoutBindings[1].descriptorType = VK_DESCRIPTOR_TYPE_STORAGE_BUFFER;
layoutBindings[1].pImmutableSamplers = nullptr;
layoutBindings[1].stageFlags = VK_SHADER_STAGE_COMPUTE_BIT;
layoutBindings[2].binding = 2;
layoutBindings[2].descriptorCount = 1;
layoutBindings[2].descriptorType = VK_DESCRIPTOR_TYPE_STORAGE_BUFFER;
layoutBindings[2].pImmutableSamplers = nullptr;
layoutBindings[2].stageFlags = VK_SHADER_STAGE_COMPUTE_BIT;
VkDescriptorSetLayoutCreateInfo layoutInfo{};
layoutInfo.sType = VK_STRUCTURE_TYPE_DESCRIPTOR_SET_LAYOUT_CREATE_INFO;
layoutInfo.bindingCount = 3;
layoutInfo.pBindings = layoutBindings.data();
if (vkCreateDescriptorSetLayout(device, &layoutInfo, nullptr, &computeDescriptorSetLayout) != VK_SUCCESS) {
throw std::runtime_error("failed to create compute descriptor set layout!");
}
查看此设置,您可能会想知道为什么我们对着色器存储缓冲对象有两个布局绑定,即使我们只渲染单个粒子系统。这是因为粒子位置是逐帧更新的,基于增量时间。这意味着每一帧都需要了解上一帧的粒子位置,以便可以使用新的增量时间更新它们,并将它们写入自己的 SSBO

为此,计算着色器需要访问上一帧和当前帧的 SSBO。这是通过在我们的描述符设置中将两者都传递给计算着色器来完成的。请参阅 storageBufferInfoLastFrame 和 storageBufferInfoCurrentFrame
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
VkDescriptorBufferInfo uniformBufferInfo{};
uniformBufferInfo.buffer = uniformBuffers[i];
uniformBufferInfo.offset = 0;
uniformBufferInfo.range = sizeof(UniformBufferObject);
std::array<VkWriteDescriptorSet, 3> descriptorWrites{};
...
VkDescriptorBufferInfo storageBufferInfoLastFrame{};
storageBufferInfoLastFrame.buffer = shaderStorageBuffers[(i - 1) % MAX_FRAMES_IN_FLIGHT];
storageBufferInfoLastFrame.offset = 0;
storageBufferInfoLastFrame.range = sizeof(Particle) * PARTICLE_COUNT;
descriptorWrites[1].sType = VK_STRUCTURE_TYPE_WRITE_DESCRIPTOR_SET;
descriptorWrites[1].dstSet = computeDescriptorSets[i];
descriptorWrites[1].dstBinding = 1;
descriptorWrites[1].dstArrayElement = 0;
descriptorWrites[1].descriptorType = VK_DESCRIPTOR_TYPE_STORAGE_BUFFER;
descriptorWrites[1].descriptorCount = 1;
descriptorWrites[1].pBufferInfo = &storageBufferInfoLastFrame;
VkDescriptorBufferInfo storageBufferInfoCurrentFrame{};
storageBufferInfoCurrentFrame.buffer = shaderStorageBuffers[i];
storageBufferInfoCurrentFrame.offset = 0;
storageBufferInfoCurrentFrame.range = sizeof(Particle) * PARTICLE_COUNT;
descriptorWrites[2].sType = VK_STRUCTURE_TYPE_WRITE_DESCRIPTOR_SET;
descriptorWrites[2].dstSet = computeDescriptorSets[i];
descriptorWrites[2].dstBinding = 2;
descriptorWrites[2].dstArrayElement = 0;
descriptorWrites[2].descriptorType = VK_DESCRIPTOR_TYPE_STORAGE_BUFFER;
descriptorWrites[2].descriptorCount = 1;
descriptorWrites[2].pBufferInfo = &storageBufferInfoCurrentFrame;
vkUpdateDescriptorSets(device, 3, descriptorWrites.data(), 0, nullptr);
}
请记住,我们还必须从描述符池中请求 SSBO 的描述符类型
std::array<VkDescriptorPoolSize, 2> poolSizes{};
...
poolSizes[1].type = VK_DESCRIPTOR_TYPE_STORAGE_BUFFER;
poolSizes[1].descriptorCount = static_cast<uint32_t>(MAX_FRAMES_IN_FLIGHT) * 2;
我们需要将从池中请求的 VK_DESCRIPTOR_TYPE_STORAGE_BUFFER 类型数量加倍,因为我们的集合引用了上一帧和当前帧的 SSBO。
计算管线
由于计算不是图形管线的一部分,因此我们无法使用 vkCreateGraphicsPipelines。相反,我们需要使用 vkCreateComputePipelines 创建专用的计算管线,以运行我们的计算命令。由于计算管线不涉及任何光栅化状态,因此它的状态比图形管线少得多
VkComputePipelineCreateInfo pipelineInfo{};
pipelineInfo.sType = VK_STRUCTURE_TYPE_COMPUTE_PIPELINE_CREATE_INFO;
pipelineInfo.layout = computePipelineLayout;
pipelineInfo.stage = computeShaderStageInfo;
if (vkCreateComputePipelines(device, VK_NULL_HANDLE, 1, &pipelineInfo, nullptr, &computePipeline) != VK_SUCCESS) {
throw std::runtime_error("failed to create compute pipeline!");
}
设置要简单得多,因为我们只需要一个着色器阶段和一个管线布局。管线布局的工作方式与图形管线相同
VkPipelineLayoutCreateInfo pipelineLayoutInfo{};
pipelineLayoutInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_LAYOUT_CREATE_INFO;
pipelineLayoutInfo.setLayoutCount = 1;
pipelineLayoutInfo.pSetLayouts = &computeDescriptorSetLayout;
if (vkCreatePipelineLayout(device, &pipelineLayoutInfo, nullptr, &computePipelineLayout) != VK_SUCCESS) {
throw std::runtime_error("failed to create compute pipeline layout!");
}
计算空间
在我们深入了解计算着色器的工作原理以及如何向 GPU 提交计算 workload 之前,我们需要讨论两个重要的计算概念:工作组和 调用。它们定义了一个抽象执行模型,用于说明 GPU 的计算硬件如何在三个维度(x、y 和 z)中处理计算 workload。
工作组 定义了 GPU 的计算硬件如何形成和处理计算 workload。您可以将它们视为 GPU 必须完成的工作项。工作组维度由应用程序在命令缓冲时间使用分发命令设置。
然后,每个工作组都是执行相同计算着色器的 调用 的集合。调用可以潜在地并行运行,它们的维度在计算着色器中设置。单个工作组内的调用可以访问共享内存。
此图像显示了这三者之间的关系

工作组的维度数量(由 vkCmdDispatch 定义)和调用取决于(由计算着色器中的局部大小定义)输入数据的结构。例如,如果您处理一维数组(就像我们在本章中所做的那样),您只需要为两者指定 x 维度。
例如:如果我们分发 [64, 1, 1] 的工作组计数,计算着色器局部大小为 [32, 32, ,1],则我们的计算着色器将被调用 64 x 32 x 32 = 65,536 次。
请注意,工作组和局部大小的最大计数因实现而异,因此您应始终在 VkPhysicalDeviceLimits 中检查与计算相关的 maxComputeWorkGroupCount、maxComputeWorkGroupInvocations 和 maxComputeWorkGroupSize 限制。
计算着色器
现在我们已经了解了设置计算着色器管线所需的所有部分,现在是时候看看计算着色器了。我们了解到的关于使用 GLSL 着色器(例如用于顶点和片段着色器)的所有内容也适用于计算着色器。语法相同,并且应用程序和着色器之间传递数据等许多概念也相同。但也有一些重要的区别。
用于更新粒子线性数组的非常基本的计算着色器可能如下所示
#version 450
layout (binding = 0) uniform ParameterUBO {
float deltaTime;
} ubo;
struct Particle {
vec2 position;
vec2 velocity;
vec4 color;
};
layout(std140, binding = 1) readonly buffer ParticleSSBOIn {
Particle particlesIn[ ];
};
layout(std140, binding = 2) buffer ParticleSSBOOut {
Particle particlesOut[ ];
};
layout (local_size_x = 256, local_size_y = 1, local_size_z = 1) in;
void main()
{
uint index = gl_GlobalInvocationID.x;
Particle particleIn = particlesIn[index];
particlesOut[index].position = particleIn.position + particleIn.velocity.xy * ubo.deltaTime;
particlesOut[index].velocity = particleIn.velocity;
...
}
着色器的顶部部分包含着色器输入的声明。首先是绑定 0 处的 uniform 缓冲对象,这是我们已经在本教程中了解到的。下面我们声明了与 C++ 代码中的声明匹配的 Particle 结构。然后,绑定 1 引用来自上一帧的粒子数据的着色器存储缓冲对象(请参阅描述符设置),绑定 2 指向当前帧的 SSBO,这是我们将使用此着色器更新的 SSBO。
一个有趣的事情是这个与计算空间相关的仅计算声明
layout (local_size_x = 256, local_size_y = 1, local_size_z = 1) in;
这定义了当前工作组中此计算着色器的调用次数。如前所述,这是计算空间的局部部分。因此带有 local_ 前缀。由于我们处理的是粒子的线性 1D 数组,因此我们只需要在 local_size_x 中指定 x 维度的数字。
然后,main 函数从上一帧的 SSBO 读取,并将更新后的粒子位置写入当前帧的 SSBO。与其他着色器类型类似,计算着色器有自己的一组内置输入变量。内置变量始终以 gl_ 为前缀。其中一个内置变量是 gl_GlobalInvocationID,这是一个唯一标识当前分发中当前计算着色器调用的变量。我们使用它来索引到我们的粒子数组中。
运行计算命令
分发
现在是时候真正告诉 GPU 进行一些计算了。这是通过在命令缓冲内调用 vkCmdDispatch 完成的。虽然不完全正确,但分发对于计算就像 vkCmdDraw 对于图形的绘制调用一样。这在最多三个维度中分发给定数量的计算工作项。
VkCommandBufferBeginInfo beginInfo{};
beginInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO;
if (vkBeginCommandBuffer(commandBuffer, &beginInfo) != VK_SUCCESS) {
throw std::runtime_error("failed to begin recording command buffer!");
}
...
vkCmdBindPipeline(commandBuffer, VK_PIPELINE_BIND_POINT_COMPUTE, computePipeline);
vkCmdBindDescriptorSets(commandBuffer, VK_PIPELINE_BIND_POINT_COMPUTE, computePipelineLayout, 0, 1, &computeDescriptorSets[i], 0, 0);
vkCmdDispatch(computeCommandBuffer, PARTICLE_COUNT / 256, 1, 1);
...
if (vkEndCommandBuffer(commandBuffer) != VK_SUCCESS) {
throw std::runtime_error("failed to record command buffer!");
}
vkCmdDispatch 将在 x 维度中分发 PARTICLE_COUNT / 256 个局部工作组。由于我们的粒子数组是线性的,因此我们将其他两个维度保留为一,从而产生一维分发。但是,我们为什么要将粒子(在我们的数组中)的数量除以 256 呢?那是因为在上一段中,我们定义了工作组中的每个计算着色器将执行 256 次调用。因此,如果我们有 4096 个粒子,我们将分发 16 个工作组,每个工作组运行 256 个计算着色器调用。正确获得这两个数字通常需要一些调整和分析,具体取决于您的 workload 和您运行的硬件。如果您的粒子大小是动态的并且不能总是被例如 256 整除,您始终可以在计算着色器的开头使用 gl_GlobalInvocationID,如果全局调用索引大于您的粒子数,则从计算着色器返回。
就像计算管线的情况一样,计算命令缓冲包含的状态比图形命令缓冲少得多。无需启动渲染通道或设置视口。
提交工作
由于我们的示例同时执行计算和图形操作,因此我们将为每个帧向图形和计算队列提交两次(请参阅 drawFrame 函数)
...
if (vkQueueSubmit(computeQueue, 1, &submitInfo, nullptr) != VK_SUCCESS) {
throw std::runtime_error("failed to submit compute command buffer!");
};
...
if (vkQueueSubmit(graphicsQueue, 1, &submitInfo, inFlightFences[currentFrame]) != VK_SUCCESS) {
throw std::runtime_error("failed to submit draw command buffer!");
}
第一次提交到计算队列使用计算着色器更新粒子位置,第二次提交将使用更新后的数据来绘制粒子系统。
同步图形和计算
同步是 Vulkan 的重要组成部分,尤其是在结合图形进行计算时更是如此。错误或缺乏同步可能会导致顶点阶段开始绘制(=读取)粒子,而计算着色器尚未完成更新(=写入)它们(写后读冒险),或者计算着色器可能开始更新仍被管线的顶点部分使用的粒子(读后写冒险)。
因此,我们必须通过正确同步图形和计算负载来确保不会发生这些情况。有不同的方法可以做到这一点,具体取决于您提交计算 workload 的方式,但在我们的案例中,使用两次单独的提交,我们将使用 信号量 和 围栏 来确保在计算着色器完成更新顶点之前,顶点着色器不会开始获取顶点。
这是必要的,因为即使两个提交是一个接一个排序的,也不能保证它们在 GPU 上按此顺序执行。添加等待和信号信号量可确保此执行顺序。
因此,我们首先在 createSyncObjects 中为计算工作添加一组新的同步图元。计算围栏与图形围栏一样,在已发出信号状态下创建,因为否则,第一次绘制将在等待围栏发出信号时超时,如 此处 详细说明。
std::vector<VkFence> computeInFlightFences;
std::vector<VkSemaphore> computeFinishedSemaphores;
...
computeInFlightFences.resize(MAX_FRAMES_IN_FLIGHT);
computeFinishedSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
VkSemaphoreCreateInfo semaphoreInfo{};
semaphoreInfo.sType = VK_STRUCTURE_TYPE_SEMAPHORE_CREATE_INFO;
VkFenceCreateInfo fenceInfo{};
fenceInfo.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO;
fenceInfo.flags = VK_FENCE_CREATE_SIGNALED_BIT;
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
...
if (vkCreateSemaphore(device, &semaphoreInfo, nullptr, &computeFinishedSemaphores[i]) != VK_SUCCESS ||
vkCreateFence(device, &fenceInfo, nullptr, &computeInFlightFences[i]) != VK_SUCCESS) {
throw std::runtime_error("failed to create compute synchronization objects for a frame!");
}
}
然后我们使用它们将计算缓冲提交与图形提交同步
// Compute submission
vkWaitForFences(device, 1, &computeInFlightFences[currentFrame], VK_TRUE, UINT64_MAX);
updateUniformBuffer(currentFrame);
vkResetFences(device, 1, &computeInFlightFences[currentFrame]);
vkResetCommandBuffer(computeCommandBuffers[currentFrame], /*VkCommandBufferResetFlagBits*/ 0);
recordComputeCommandBuffer(computeCommandBuffers[currentFrame]);
submitInfo.commandBufferCount = 1;
submitInfo.pCommandBuffers = &computeCommandBuffers[currentFrame];
submitInfo.signalSemaphoreCount = 1;
submitInfo.pSignalSemaphores = &computeFinishedSemaphores[currentFrame];
if (vkQueueSubmit(computeQueue, 1, &submitInfo, computeInFlightFences[currentFrame]) != VK_SUCCESS) {
throw std::runtime_error("failed to submit compute command buffer!");
};
// Graphics submission
vkWaitForFences(device, 1, &inFlightFences[currentFrame], VK_TRUE, UINT64_MAX);
...
vkResetFences(device, 1, &inFlightFences[currentFrame]);
vkResetCommandBuffer(commandBuffers[currentFrame], /*VkCommandBufferResetFlagBits*/ 0);
recordCommandBuffer(commandBuffers[currentFrame], imageIndex);
VkSemaphore waitSemaphores[] = { computeFinishedSemaphores[currentFrame], imageAvailableSemaphores[currentFrame] };
VkPipelineStageFlags waitStages[] = { VK_PIPELINE_STAGE_VERTEX_INPUT_BIT, VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT };
submitInfo = {};
submitInfo.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO;
submitInfo.waitSemaphoreCount = 2;
submitInfo.pWaitSemaphores = waitSemaphores;
submitInfo.pWaitDstStageMask = waitStages;
submitInfo.commandBufferCount = 1;
submitInfo.pCommandBuffers = &commandBuffers[currentFrame];
submitInfo.signalSemaphoreCount = 1;
submitInfo.pSignalSemaphores = &renderFinishedSemaphores[currentFrame];
if (vkQueueSubmit(graphicsQueue, 1, &submitInfo, inFlightFences[currentFrame]) != VK_SUCCESS) {
throw std::runtime_error("failed to submit draw command buffer!");
}
与 信号量章节 中的示例类似,此设置将立即运行计算着色器,因为我们尚未指定任何等待信号量。这很好,因为我们正在等待当前帧的计算命令缓冲在计算提交之前完成执行,使用 vkWaitForFences 命令。
另一方面,图形提交需要等待计算工作完成,因此在计算缓冲仍在更新顶点时,它不会开始获取顶点。因此,我们在当前帧的 computeFinishedSemaphores 上等待,并让图形提交在消耗顶点的 VK_PIPELINE_STAGE_VERTEX_INPUT_BIT 阶段等待。
但它还需要等待呈现,因此在图像呈现之前,片段着色器不会输出到颜色附件。因此,我们还在 VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT 阶段等待当前帧的 imageAvailableSemaphores。
绘制粒子系统
早些时候,我们了解到 Vulkan 中的缓冲可以有多种用例,因此我们创建了着色器存储缓冲,其中包含我们的粒子,同时具有着色器存储缓冲位和顶点缓冲位。这意味着我们可以像在之前的章节中使用“纯”顶点缓冲一样使用着色器存储缓冲进行绘制。
我们首先设置顶点输入状态以匹配我们的粒子结构
struct Particle {
...
static std::array<VkVertexInputAttributeDescription, 2> getAttributeDescriptions() {
std::array<VkVertexInputAttributeDescription, 2> attributeDescriptions{};
attributeDescriptions[0].binding = 0;
attributeDescriptions[0].location = 0;
attributeDescriptions[0].format = VK_FORMAT_R32G32_SFLOAT;
attributeDescriptions[0].offset = offsetof(Particle, position);
attributeDescriptions[1].binding = 0;
attributeDescriptions[1].location = 1;
attributeDescriptions[1].format = VK_FORMAT_R32G32B32A32_SFLOAT;
attributeDescriptions[1].offset = offsetof(Particle, color);
return attributeDescriptions;
}
};
请注意,我们没有将 velocity 添加到顶点输入属性,因为它仅供计算着色器使用。
然后我们像使用任何顶点缓冲一样绑定和绘制它
vkCmdBindVertexBuffers(commandBuffer, 0, 1, &shaderStorageBuffer[currentFrame], offsets);
vkCmdDraw(commandBuffer, PARTICLE_COUNT, 1, 0, 0);
结论
在本章中,我们学习了如何使用计算着色器将工作从 CPU 卸载到 GPU。如果没有计算着色器,现代游戏和应用程序中的许多效果要么不可能实现,要么运行速度会慢得多。但即使超过图形,计算也有很多用例,本章仅让您了解可能的用途。因此,既然您知道如何使用计算着色器,您可能需要查看一些高级计算主题,例如
您可以在 官方 Khronos Vulkan 示例仓库 中找到一些高级计算示例。